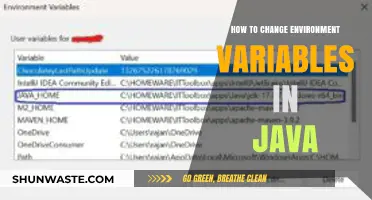
Changing environment variables in Jenkins is a common task for customizing build and deployment processes. Jenkins allows you to define and modify environment variables at both the global and job-specific levels, providing flexibility for different project requirements. To change environment variables globally, navigate to the Jenkins dashboard, go to Manage Jenkins > Configure System, and locate the Global Properties section where you can add or edit environment variables. For job-specific variables, access the job configuration page, find the Build Environment or Environment Variables section, and add key-value pairs as needed. Additionally, environment variables can be set dynamically within pipelines using the `env` directive in Jenkinsfiles. Understanding these methods ensures efficient management of environment variables, enabling seamless integration with various tools and workflows in your CI/CD pipeline.
Explore related products






What You'll Learn
![]()
Setting Variables in Jenkins Pipeline
Jenkins Pipeline, a suite of plugins supporting the integration and implementation of continuous delivery pipelines, offers a robust mechanism for managing environment variables directly within your pipeline scripts. This capability is crucial for maintaining flexibility and security in your CI/CD processes. By setting variables in the pipeline, you can dynamically configure build steps, control behavior based on conditions, and securely manage sensitive information like credentials or API keys.
Declarative vs. Scripted Pipelines: The approach to setting variables differs slightly between Declarative and Scripted pipelines. In Declarative pipelines, which are more structured and opinionated, you typically define environment variables within the `environment` directive at the pipeline or stage level. For instance, `environment { MY_VAR = 'value' }` sets a variable accessible throughout the pipeline. Scripted pipelines, offering more flexibility and control, allow variable assignment using Groovy syntax, such as `def myVar = 'value'`, which can be scoped to specific sections of the script.
Best Practices for Variable Management: When setting variables in Jenkins Pipeline, consider scoping them to the smallest necessary context to minimize unintended side effects. For sensitive data, leverage Jenkins’ built-in credentials binding feature, which securely injects credentials as environment variables during runtime. Additionally, use parameterised pipelines to externalise configuration, allowing variables to be passed dynamically at runtime, enhancing reusability and adaptability.
Dynamic Variable Assignment: Jenkins Pipeline supports dynamic variable assignment, enabling you to set values based on conditions, external inputs, or script logic. For example, you can assign a variable based on the current branch name using `${env.BRANCH_NAME}`, or compute a value within a script block. This dynamism is particularly useful for implementing branch-specific configurations or environment-aware behaviors.
Example Implementation: Consider a scenario where you need to deploy an application to different environments (e.g., staging, production) based on a parameter. In a Declarative pipeline, you might define:
Groovy
Pipeline {
Agent any
Parameters {
Choice(name: 'ENV', choices: ['staging', 'production'], description: 'Target environment')
}
Environment {
DEPLOY_URL = "${params.ENV == 'staging' ? 'https://staging.example.com' : 'https://production.example.com'}"
}
Stages {
Stage('Deploy') {
Steps {
Echo "Deploying to ${DEPLOY_URL}"
// Deployment commands here
}
}
}
}
This example demonstrates conditional variable assignment and parameterisation, showcasing the flexibility of setting variables in Jenkins Pipeline.
By mastering variable management in Jenkins Pipeline, you can create more maintainable, secure, and adaptable CI/CD workflows tailored to your project’s needs. Whether through declarative directives, scripted logic, or dynamic assignments, Jenkins provides the tools to manage environment variables effectively at every stage of your pipeline.
Leeches' Ecological Role: Uncovering Their Environmental Benefits and Impact
You may want to see also
Explore related products






![]()
Using 'env' Directive in Jenkinsfile
The `env` directive in a Jenkinsfile provides a declarative way to define environment variables directly within your pipeline script. This approach is particularly useful for setting variables that are specific to a stage or the entire pipeline, ensuring they are available to all steps within the defined scope. Unlike setting variables via the Jenkins UI or command-line, the `env` directive offers a version-controlled, reproducible method for managing environment variables.
To use the `env` directive, you simply include it within the appropriate block of your Jenkinsfile. For instance, to set variables globally for the entire pipeline, place the `env` directive at the top level of your pipeline block. If you need variables specific to a stage, nest the `env` directive within that stage. Here’s an example of setting global environment variables:
Groovy
Pipeline {
Agent any
Environment {
APP_NAME = 'MyApplication'
BUILD_NUMBER = '1.0.0'
}
Stages {
Stage('Build') {
Steps {
Echo "Building ${APP_NAME} version ${BUILD_NUMBER}"
}
}
}
}
In this example, `APP_NAME` and `BUILD_NUMBER` are accessible throughout the pipeline. The `env` directive supports both string literals and references to other environment variables, allowing for dynamic variable creation. For instance, you can concatenate values or reference predefined Jenkins environment variables like `BUILD_ID` or `JOB_NAME`.
One key advantage of the `env` directive is its ability to override variables. If a variable is defined both globally and within a specific stage, the stage-level definition takes precedence. This feature enables fine-grained control over variable values, depending on the context in which they are used. However, be cautious when overriding variables, as it can lead to unintended behavior if not managed carefully.
While the `env` directive is powerful, it’s not the only way to manage environment variables in Jenkins. For temporary or sensitive variables, consider using the `withEnv` step or injecting credentials via the Jenkins Credentials Plugin. The `env` directive shines when variables need to be consistently defined across multiple stages or pipelines, offering a clean, declarative solution for environment variable management.
Rubbish's Devastating Impact: How Waste Harms Our Environment and Wildlife
You may want to see also
Explore related products



$32.47 $65.99



![]()
Global Environment Variables Configuration
Jenkins, a widely-used automation server, allows users to manage environment variables at both the job and global levels. Global environment variables are particularly useful when you need to apply consistent configurations across multiple jobs without redundancy. To configure these, navigate to the Jenkins dashboard, click "Manage Jenkins," and then select "Configure System." Scroll down to the "Global Properties" section and check the box labeled "Environment variables." Here, you can add key-value pairs that will be available to all jobs by default. For instance, setting `JAVA_HOME=/usr/lib/jvm/java-11-openjdk` ensures all builds use the specified Java version, eliminating the need to define it repeatedly.
While global variables offer convenience, their misuse can lead to unintended consequences. For example, setting a global variable like `BUILD_ENV=production` might inadvertently expose sensitive configurations if not carefully managed. To mitigate risks, adopt a naming convention that distinguishes global variables, such as prefixing them with `GLOBAL_` (e.g., `GLOBAL_API_KEY`). Additionally, leverage Jenkins' "Credentials Binding" plugin to securely inject sensitive values, ensuring they remain encrypted and accessible only to authorized jobs. This approach balances flexibility with security, a critical consideration in shared Jenkins environments.
Another practical tip is to override global variables at the job level when necessary. Jenkins prioritizes job-specific variables over global ones, allowing you to customize behavior without altering the global configuration. For instance, if a specific job requires a different Java version, define `JAVA_HOME` within that job's configuration to override the global setting. This hierarchical approach ensures consistency while accommodating exceptions, making your pipeline more adaptable to diverse requirements.
Finally, consider using scripts or tools to manage global variables dynamically. Jenkins supports Groovy scripts, which can be executed via the "Script Console" to automate variable updates. For example, a script could fetch the latest Java path from a configuration file and update the global `JAVA_HOME` variable accordingly. This method is particularly useful in environments where dependencies frequently change, reducing manual intervention and minimizing errors. By combining global variables with automation, you can create a robust and scalable Jenkins configuration.
Remediation's Role in Shaping Today's Media Landscape and Culture
You may want to see also
Explore related products






![]()
Passing Variables via Build Parameters
Jenkins, a widely-used automation server, offers a flexible way to manage environment variables through build parameters. These parameters allow you to pass dynamic values into your build process, making your pipelines more adaptable and reusable. By leveraging build parameters, you can avoid hardcoding values directly into your Jenkinsfile or job configuration, which enhances maintainability and reduces errors.
To pass variables via build parameters, start by defining them in your Jenkins job configuration. Navigate to your job, click "Configure," and scroll down to the "Build Parameters" section. Here, you can add parameters of various types, such as string, boolean, or choice parameters. For instance, a string parameter named `ENVIRONMENT` could be used to specify whether the build should target `dev`, `staging`, or `production`. Once defined, these parameters become available as environment variables during the build execution, accessible via `${PARAMETER_NAME}` syntax.
One of the key advantages of using build parameters is their ability to integrate seamlessly with pipelines. In a Jenkinsfile, you can reference these parameters directly within stages, steps, or scripts. For example, a declarative pipeline might include a stage like `environment: "${ENVIRONMENT}"`, dynamically setting the environment based on the parameter value. This approach ensures that your pipeline remains consistent across different contexts without requiring manual intervention.
However, it’s crucial to handle sensitive information carefully when using build parameters. While they are convenient for non-sensitive data, secrets like API keys or passwords should be managed through Jenkins' Credentials Binding plugin or environment variables injected via the job configuration. This practice minimizes the risk of exposing sensitive data in logs or build histories.
In summary, passing variables via build parameters in Jenkins provides a powerful mechanism for customizing builds while maintaining flexibility. By defining parameters in the job configuration and referencing them in pipelines, you can create dynamic, context-aware workflows. Just remember to prioritize security by avoiding the use of build parameters for sensitive data, opting instead for dedicated credential management solutions. This method not only streamlines your CI/CD processes but also ensures scalability and security in your automation workflows.
Logging's Environmental Impact: Effects on Ecosystems, Climate, and Biodiversity
You may want to see also
Explore related products






![]()
Managing Secrets with Credentials Plugin
Storing sensitive data like API keys, passwords, and tokens directly in Jenkins environment variables is a security risk. The Credentials Plugin offers a secure alternative, allowing you to manage secrets centrally and inject them into builds as needed.
Think of it as a locked vault within Jenkins, accessible only to authorized users and jobs.
Securing Your Secrets: The Credentials Plugin Workflow
Here's a breakdown of how it works:
- Create Credentials: Within Jenkins, navigate to "Manage Jenkins" > "Manage Credentials". Choose the appropriate credential type (e.g., Secret Text, Username with Password) and provide the necessary details.
- Bind Credentials to Jobs: In your Jenkins job configuration, locate the "Build Environment" or "Environment Variables" section. Instead of hardcoding sensitive values, select the credential you created from the available options.
- Access in Builds: During job execution, Jenkins securely retrieves the credential value and makes it available as an environment variable within the build environment.
Beyond Basic Storage: Advanced Features
The Credentials Plugin goes beyond simple storage. It offers features like:
- Credential Masking: Hide sensitive values in logs and console output, preventing accidental exposure.
- Credential Scoping: Restrict access to credentials based on job or folder, ensuring only authorized builds can use them.
- Credential Providers: Integrate with external secret management systems like HashiCorp Vault or AWS Secrets Manager for even greater security and scalability.
Best Practices for Secure Secret Management
- Principle of Least Privilege: Grant access to credentials only to the jobs that absolutely need them.
- Regular Rotation: Periodically update your secrets to minimize the impact of potential breaches.
- Audit Logs: Enable auditing to track credential usage and identify any suspicious activity.
By leveraging the Credentials Plugin, you can significantly enhance the security of your Jenkins pipelines, protecting sensitive data and maintaining the integrity of your builds.
Bumblebees: Essential Pollinators and Their Environmental Impact Explained
You may want to see also
Frequently asked questions
To set environment variables globally in Jenkins, go to Manage Jenkins > Configure System, then scroll down to the Global Properties section. Check the Environment variables option, add your variable name and value, and save the configuration.
Yes, you can set environment variables at the job level by navigating to your job's configuration page, adding a Build Environment section if not present, and using the Inject environment variables option to define your variables.
In a Jenkins pipeline, use the `environment` directive within your pipeline script to define environment variables. For example:
```groovy
pipeline {
environment {
MY_VAR = 'my_value'
}
// stages and steps
}
```
Yes, you can override environment variables in a specific stage by using the `environment` directive within that stage. For example:
```groovy
stage('Build') {
environment {
MY_VAR = 'stage_specific_value'
}
steps {
// stage steps
}
}
```
To verify environment variables, you can print them in your build script using `echo` or `println` in a pipeline. For example:
```groovy
sh 'echo $MY_VAR'
```
Alternatively, check the console output of your build for the variable values.






![Jeanette Jenkins: Hollywood Trainer 21 Day Total Body Circuit [DVD]](https://m.media-amazon.com/images/I/51aH9yGHCzL._AC_UL320_.jpg)